BC-250를 활용한 AI 프로젝트: 준비
LLM으로 보안관제 비서 만들어보기!
1. BC-250이란?
BC-250은 일반적인 데스크톱 PC라기보다는,
PlayStation 5 APU 계열과 연관된 것으로 알려진
AMD Cyan Skillfish 계열 APU 기반 특수 가상화폐 채굴용 보드다.
출처:민티저
구성은 대략 다음과 같다.
- Zen 2 기반 CPU
- RDNA 계열 GPU
- 16GB GDDR6 공유 메모리
- 일반 DDR4/DDR5 메모리 슬롯이 없는 구조
- 일반 PC보다는 채굴용·임베디드·특수 목적 보드에 가까운 형태
즉 BC250은 일반적인 그래픽카드도 아니고,
일반적인 미니 PC도 아니다.
구조만 놓고 보면
PS5나 닌텐도 스위치 같은 콘솔형 APU 기기 구조와 비슷하다,
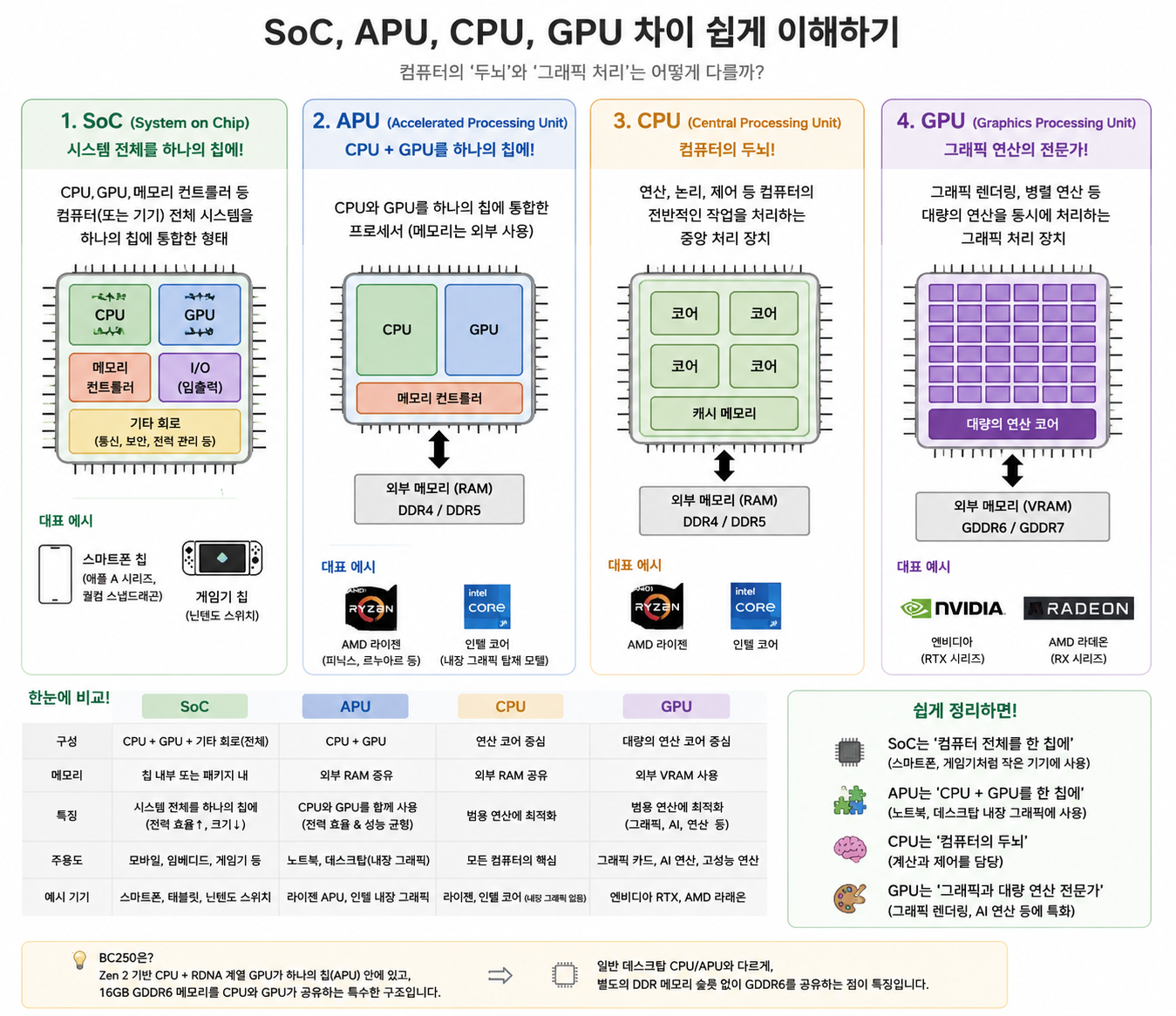
다만 일반적인 데스크톱의 APU와 다른점은
별도의 일반 메모리 슬롯 없이 16GB GDDR6 메모리를 CPU와 GPU가 공유한다.
이 특성 때문에 일반적인 데스크톱처럼 쓰기에는 제약이 있다.
설치 자체가 완전히 불가능한 것은 아니지만,
특수 목적 보드에 가까운 장비이다 보니 드라이버 지원이 제한적이다.
이 때문에 일부 환경에서는
프로그램 실행 실패,
프로그램 종료,
GPU 가속 실패,
idle/작업 중 전력소비가 큼같은 문제가 발생할 수 있다.
BC-250관련 글들을 보면 AI 추론보다는
BazziteOS를 설치해 SteamDeck 머신으로 활용하는 사례가 더 많이 보인다.
2. 왜 BC-250으로 LLM을 돌리려 했나?
처음 목적은 단순했다.
AI 학과를 나왔지만,
수업시간에 잠들거나... 대학라이프를 즐긴다며...
도망가기 바빴지,
모델을 직접 학습시킨다던가, 로컬LLM을 직접 돌린다던가,
API를 활용해 프로젝트를 진행하진 않았다.
대화형 AI가 보급화가 막 시작될 쯤인 2022년에도
AI에 관심을 가지는 비전공자들은 있었지만,
지금처럼 LLM이나 이미지 생성 AI가 널리 쓰이는 분위기까지는 아니었다.





상용 대화형 AI
필자 역시 학부생, 개발직으로 있을 때
코딩이나, 일상생활에 많은 참고용 자료로 쓴지는 꽤 됐었고,
과거랑 지금을 비교하면,
대화형 AI 서비스도 종류가 늘었고,
대답 품질이나, 언어 이해도 같은 영역 뿐만 아니라
이미지 생성, 디바이스 제어 같은 보조 도구 활용 등
체감이 될 정도로 AI 발전이 빠르게 느껴진다.
그 때문인가?
최근에는 회사나 주변 지인들도 LLM,
이미지 생성, AI 자동화에 관심을 가지는 경우가 많아졌다.
거기에 더해 예전보다
경량화된 모델들의 품질도 많이 좋아졌다.
예전에는 작은 모델이라고 하면
성능이나 응답 품질에서 아쉬운 부분이 많았지만,
최근에는 7B~8B급 모델 중에서도
한국어 응답이나 요약 품질이 꽤 쓸 만한 모델들이 보이기 시작했다.
그 모습을 보면서
나도 다시 AI 쪽을 들여다봐야겠다는 생각이 들었다
그런데 로컬에서 LLM을 돌리려고 하니 장비 선택이 애매했다.
메인PC를 LLM 추론에 쓰자니
게임이나, 다른 작업 때문에 영향이 클 것이고
코어서버에 올리면 한쪽에 너무 큰 서비스들이 몰리며,
엣지서버는 ARM 기반 Soc라 로컬로 LLM을 돌리기엔 부담이 크다.
OpenClaw나 OpenAI, Gemini 같은 API를 연동하자니,
비용문제, 민감데이터 전송 문제도 발생한다.
게다가 원룸이다 보니,
부피가 큰 서버용 케이스를 더 두거나, PC 케이스는 부담이 좀 된다.
그러다 유튜브에서 본 BC250라면
GPU도 활용되고, 메모리가 16GB 정도 되니,
OS, 추론엔진에 사용되는 메모리를 고려하더라도
'경량 LLM 모델로
추론 정도는
시도해볼 수 있지 않을까?'
라는 생각이 들었다
물론 BC-250은 자료가 많은 장비는 아니다.
찾아보면 이미 비슷한 시도를 한 사례들이 있다.
https://github.com/akandr/bc250
Mesa/RADV Vulkan, Ollama 기반 로컬 AI 서버로 활용한 사례를
정리하고 있다.
그렇다면 로컬 LLM으로 무엇을 할 수 있을까?
처음에는 단순한 챗봇이나 개인 비서 정도를 생각했다.
더 실용적인 용도가 떠올랐다.
나는 프로젝트 관리용으로 로컬 Git 서버를 열어두고 있었다.
회사에서도 git 명령어를 쓰려고 외부에도 열어두긴 하였지만,
회원가입은 비활성화했고, 로그인도 필수로 설정했으며,
모든 저장소도 비공개로 두었다.
그런데 서비스를 운용한 지 2일 정도 지나자 외부 스캐너가
훑고 간 흔적이 로그에 잡히기 시작했다.
블로그 로그에서도 늘 겪는 문제지만
악성 스캐너들이 제법 있다.
/.git/config
/.env
/wp-login.php
/xmlrpc.php다행히 실제 민감 파일이 200 OK로 노출된 흔적은 없었고,
대부분 303 See Other 또는 404로 처리된 요청이었다.
다만 마냥 안전하다고 넘길 로그는 아니며,
지속적인 로그 확인은 필수라 생각하던 중
로컬 LLM을
단순 채팅용으로만
쓰지 말고,
서버 로그 분석
보조기로 쓰면 어떨까?
서비스가 늘어나거나 호스트가 늘어나면 로그도 여러 곳에서 쌓인다.
문제는 사람이 이 로그를 매번 직접 확인하기 어렵다는 점이다.
그래서 생각한 방향은 다음과 같다.
각 서비스 로그 수집
→ Python으로 1차 전처리
→ 로컬 LLM으로 요약
→ 이상징후 정리
→ Discord 또는 Web으로 알림즉 BC-250을 이미지생성, 컴퓨터 비전, 객체 인식과 같은
고성능 AI 서버로 쓰려는 것이 아니다.
목표는 상시 켜둘 수 있는 관제 보조 노드로 활용하는 것이다.
3. 로그 분석 Docker 이미지는 많은데?
Docker와 홈서버를 운영하다 보면 로그 분석 도구는 생각보다 많이 보인다.
| 계열 | 대표 도구 | 주요 역할 |
|---|---|---|
| 로그 수집 | Fluent Bit, Fluentd, Vector, Promtail | 컨테이너·파일 로그 수집 |
| 로그 저장/조회 | Grafana Loki, Elasticsearch, OpenSearch | 로그 저장, 검색, 인덱싱 |
| 대시보드 | Grafana, Kibana, OpenSearch Dashboards | 시각화, 조회 UI |
| 로그 관리 플랫폼 | Graylog | 로그 수집, 검색, 알림 |
| SIEM/XDR | Wazuh, Elastic Security | 보안 이벤트 탐지, 룰 기반 알림 |
| 자동화 | n8n, Shuffle | Webhook, 알림, 승인, 후속 작업 |
| 메트릭 관측 | Netdata, Prometheus | CPU, RAM, 네트워크, 서비스 상태 |
즉 로그를 모으고, 저장하고, 검색하고, 시각화하는 도구는 이미 충분히 많다.
그런데 이번에 내가 만들고 싶은 것은 단순한 로그 저장소가 아니다.
목표는 다음에 가깝다.
기존 도구들이 “로그를 모아서 보여주는 것”에 강하다면,
이번 프로젝트는 “로그를 읽고 해석해서 설명해주는 것”에 초점을 둔다.
4. 기존 로그 분석 도구의 장점과 한계
기존 도구들이 필요 없다는 뜻은 아니다.
오히려 검증된 도구들은 각자 매우 명확한 장점이 있다.
Loki나 ELK 계열은 로그를 저장하고 검색하는 데 좋다.
언제 어떤 로그가 발생했는지
특정 IP가 언제 접근했는지
특정 경로가 몇 번 요청됐는지
특정 컨테이너에서 에러가 언제 발생했는지이런 내용을 조회하기 좋다.
Fluent Bit이나 Fluentd 같은 도구는
여러 서비스에서 발생하는 로그를 한 곳으로 모으는 데 유리하다.
Graylog는
로그 수집, 검색, 알림까지 어느 정도 통합해서 다룰 수 있다.
Wazuh 같은 SIEM/XDR 계열은
보안 룰, 에이전트, 취약점 탐지, 파일 무결성 검사 같은 기능까지 제공한다.
n8n은
로그 분석 도구라기보다는 자동화 도구에 가깝다.
정해진 시간에 작업을 실행하거나, Webhook을 받고,
Discord나 메일로 알림을 보내는 데 유용하다.
즉 기존 도구들은 이미 잘 만들어져 있다.
문제는 내 홈랩 규모에서 처음부터 이걸 전부 올리는 게 맞느냐다.
처음부터 해당 이미지들을 모두 붙이면 구조가 과해진다.
이렇게 되면 관제를 위한 관제 시스템을 운영하게 된다.
처음부터 그렇게 크게 갈 필요는 없다고 판단했다.
5. 내가 필요한 것은 로그 저장소보다 로그 해석 비서다
기존 로그 도구는 보통 이런 식의 정보를 준다.
2026-06-11T09:30:59.933391061Z [2026-06-11 09:30:59] INFO source_ip: 62.60.xx.xxx method: GET path: /wp-login.php status: 303 service: gitea
2026-06-11T09:31:02.104882391Z [2026-06-11 09:31:02] INFO source_ip: 62.60.xx.xxx method: POST path: /xmlrpc.php status: 303 service: gitea
2026-06-11T09:31:05.774120488Z [2026-06-11 09:31:05] INFO source_ip: 62.60.xx.xxx method: GET path: /.git/config status: 303 service: gitea
2026-06-11T09:31:08.442901337Z [2026-06-11 09:31:08] INFO source_ip: 62.60.xx.xxx method: GET path: /.env status: 303 service: gitea
2026-06-11T09:32:14.180392551Z [2026-06-11 09:32:14] INFO source_ip: 62.60.xx.xxx method: GET path: /wp-login.php status: 404 service: ghost
2026-06-11T09:32:16.619048732Z [2026-06-11 09:32:16] INFO source_ip: 62.60.xx.xxx method: POST path: /xmlrpc.php status: 404 service: ghost
2026-06-11T09:32:20.991741228Z [2026-06-11 09:32:20] INFO source_ip: 62.60.xx.xxx method: GET path: /admin status: 404 service: ghost
2026-06-11T09:33:41.552830190Z [2026-06-11 09:33:41] INFO source_ip: 62.60.xx.xxx method: GET path: /login status: 200 service: gitea
2026-06-11T09:33:44.028112904Z [2026-06-11 09:33:44] INFO source_ip: 62.60.xx.xxx method: GET path: /admin status: 404 service: gitea
2026-06-11T09:34:12.671430885Z [2026-06-11 09:34:12] INFO source_ip: 62.60.xx.xxx method: GET path: /phpmyadmin/index.php status: 404 service: gitea정보 자체는 정확하다.
하지만 한 줄 안에
시간,
IP,
요청 방식,
경로,
상태코드,
서비스 정보
등이 섞여 있기 때문에 사람이 바로 의미를 파악하기는 어렵다.
특히 같은 IP가 Gitea, Ghost 등 여러 서비스를 짧은 시간 안에 순회했다면,
단일 로그 한 줄만 봐서는 전체 흐름을 놓치기 쉽다.
내가 원하는 출력은 단순 로그가 아니라 이런 형태다.
[최근 1시간 종합 관제 리포트]
전체 위험도: 중간
주요 관측 IP:
62.60.xx.xxx
관측된 서비스:
- Ghost
- Git
- NPM
근거:
- Ghost에 /wp-login.php, /xmlrpc.php 요청
- Gitea에 /.git/config, /.env 요청
- NPM 확인 결과 여러 도메인 짧은 시간 안에 순회
- 정상적인 사용자 탐색 흐름과 맞지 않는 경로 요청
현재 확인된 피해 흔적:
- 민감 파일 200 OK 응답은 확인되지 않음
- 인증 우회 성공 흔적 없음
- 서버 오류 유발 흔적 없음
- DB 또는 내부 API 접근 성공 흔적 없음
권장 조치:
- 동일 IP의 재접근 여부 확인
- 최근 24시간 기준 동일 IP 반복 여부 확인
- 동일 유형의 요청이 다른 IP에서도 반복되는지 확인
- 반복 시 차단 후보로 등록
- 현재 시점에서는 침해 성공보다 정찰·스캔 단계로 분류똑같진 않더라도 서비스 맥락과 로그 흐름을
사람이 읽기 좋게 정리하는 데에는 LLM이 유용하다 판단했다.
6. 기존 도구는 내 홈랩의 맥락을 모른다
홈랩에는 운영자만 아는 맥락이 있다.
예를 들면 다음과 같다.
- /small_web_project/는 일반 공개용 페이지가 아님
- Ghost의 /members/api/member/ 204는 정상 흐름
- Gitea의 303은 로그인 리다이렉션일 수 있음
- 사용자가 외부에서 VPN으로 접근하는 IP 대역
- 192.168.x.x 대역은 내부 테스트 IP
- 특정 컨테이너의 worker 로그는 정상 주기 작업기존 로그 분석 도구는 이런 맥락을 기본적으로 알지 못한다.
물론 룰로 만들 수는 있다.
하지만 모든 상황을 룰로 만들면 관리가 점점 복잡해진다.
LLM 기반 요약은 이런 환경 설명을 프롬프트나 설정으로 넣어두고,
로그를 해석할 때 참고하게 만들 수 있다.
즉 목표는 LLM에게 모든 보안 판단을 맡기는 것이 아니라,
내 홈랩의 맥락을 알고 있는 로그 해석 보조기를 만드는 것이다.
7. llama.cpp, Ollama의 차이
로컬 LLM을 다루다 보면 비슷한 이름이 많이 나온다.
llama.cpp
llama.cpp는 로컬에서 LLM을 실행하기 위한 경량 추론 엔진이다.
특징은 다음과 같다.
- GGUF 모델 직접 실행 가능
- CPU 실행 가능
- CUDA, HIP, Vulkan 같은 backend 지원
- 세밀한 옵션 조정 가능
- 직접 빌드하거나 실험하기 좋음
BC250에서는 Vulkan backend를 켜고 사용하는 방식이 중요하다.
Ollama
Ollama는 로컬 LLM을 쉽게 실행하고 관리할 수 있게 해주는 런타임/서버에 가깝다.
특징은 다음과 같다.
- 모델 다운로드와 실행이 쉬움
- API 서버처럼 사용 가능
- Open WebUI와 연동하기 쉬움
- 운영 편의성이 좋음
직접 튜닝은 llama.cpp가 더 세밀하지만, 운영 편의성은 Ollama가 좋다.
8. LLM 모델 이름 읽는 법
로컬 LLM을 쓰다 보면 다음과 같은 이름을 자주 보게 된다.
Qwen3-8B-Q5_K_M
Llama-8B-Q4_K_M
Gemma-26B-Q3
처음 보면 복잡하지만, 나눠서 보면 어렵지 않다.
B는 billion parameters, 즉 파라미터 수를 의미한다.
| 표기 | 의미 |
|---|---|
| 1B | 약 10억 파라미터 |
| 8B | 약 80억 파라미터 |
| 14B | 약 140억 파라미터 |
| 26B | 약 260억 파라미터 |
| 70B | 약 700억 파라미터 |
일반적으로 모델이 클수록 문장 이해력과 추론력이 좋아질 가능성이 높다.
하지만 그만큼 메모리 사용량과 연산량도 커진다.
BC250 기준으로는 다음 정도로 보는 것이 현실적이다.
| 모델 크기 | 판단 |
|---|---|
| 1B~4B | 매우 가볍고 빠름 |
| 7B~9B | 가장 현실적인 운영 구간 |
| 14B | 조건부 가능 |
| 26B Q3 | 실험 가능, 메모리 여유 적음 |
| 70B | 비현실적 |
관제용 요약과 분류 목적이라면 굳이 큰 모델이 필요하지 않다.
8B급 양자화 모델이면 시작하기에 충분하다.
양자화는 모델을 더 작은 비트 수로 압축하는 방식이다.
원본에 가까운 모델은 메모리를 많이 사용한다.
반대로 양자화 모델은 품질을 조금 포기하는 대신 메모리 사용량을 줄이고 실행 가능성을 높인다.
대표적인 표기는 다음과 같다.
| 표기 | 의미 | 특징 |
|---|---|---|
| Q8 | 8비트 양자화 | 품질 좋음, 무거움 |
| Q6 | 6비트 양자화 | 품질 우선 |
| Q5 | 5비트 양자화 | 품질과 메모리 균형 |
| Q4 | 4비트 양자화 | 가볍고 실사용 가능 |
| Q3 | 3비트 양자화 | 많이 압축됨, 품질 손실 체감 |
| Q2 | 2비트 양자화 | 품질 손실 큼 |
핵심은 다음이다.
숫자가 높을수록 원본에 가깝다.
숫자가 낮을수록 더 많이 압축된다.
즉 Q8은 품질은 좋지만 무겁고, Q4는 더 가볍지만 품질 손실이 있다.
Q4_K_M, Q5_K_M은 무엇인가?
예를 들어 Q5_K_M은 다음처럼 나눌 수 있다.
Q5_K_M
│ │ │
│ │ └─ M = Medium, 균형형
│ └─── K = K-quant 계열 양자화
└───── Q5 = 5비트급 양자화
대략적인 의미는 다음과 같다.
| 표기 | 의미 |
|---|---|
| Q4_0, Q4_1 | 구형 또는 단순 양자화 |
| Q4_K, Q5_K | 개선된 K-quant 계열 |
| _S | Small, 더 작고 빠름 |
| _M | Medium, 균형형 |
| _L | Large, 품질 우선 |
| Q8_0 | 8비트 양자화 |
운영용으로는 보통 다음 정도가 무난하다.
Qwen 8B Q5_K_M
Qwen 8B Q4_K_M
Q5_K_M은 품질과 메모리 사용량의 균형이 좋고, Q4_K_M은 더 가볍고 빠르다.
9. BC250에서 추천할 만한 모델
홈랩 관제 목적이라면 “최대한 큰 모델”보다 “안정적으로 계속 돌아가는 모델”이 중요하다.
추천 우선순위는 다음과 같다.
| 목적 | 추천 모델 |
|---|---|
| 운영용 | Qwen 8B Q5_K_M |
| 속도/안정성 우선 | Qwen 8B Q4_K_M |
| 품질 확인용 | Qwen 8B Q8_0 |
| 실험용 | Gemma 26B Q3 또는 MoE 저비트 모델 |
관제 시스템은 완벽한 추론보다 다음이 중요하다.
- 로그 요약
- 정상/비정상 분류
- 민감 경로 탐지 결과 설명
- 차단 후보 정리
- 사람이 읽기 쉬운 리포트 생성
이 정도라면 8B급 모델로도 충분히 시작할 수 있다.
10. 컨텍스트는 어떻게 써야 하나?
LLM의 컨텍스트는 모델이 한 번에 참고할 수 있는 입력 범위다.
컨텍스트가 길어지면
더 많은 정보를 함께 참고할 수 있다는 장점이 있다.
하지만 입력이 길어질수록 중요한 정보가 묻히거나,
모델이 서로 관련 없는 로그를 잘못 연결해 해석할 가능성도 생긴다.

흔히 말하는 ai 할루시네이션 발생 조건에 가깝다.
때문에 LLM을 통해 실시간 차단까지 이뤄지는 보안 장비처럼 쓰면 위험하다.
또한 BC250은 하드웨어 성능과 메모리 여유가 제한적인 장비이기 때문에,
큰 추론 모델이나 긴 컨텍스트를 안정적으로 다루기에는 부담이 있다.
이를 해결하고자
생각해둔 방식은 다음과 같다.
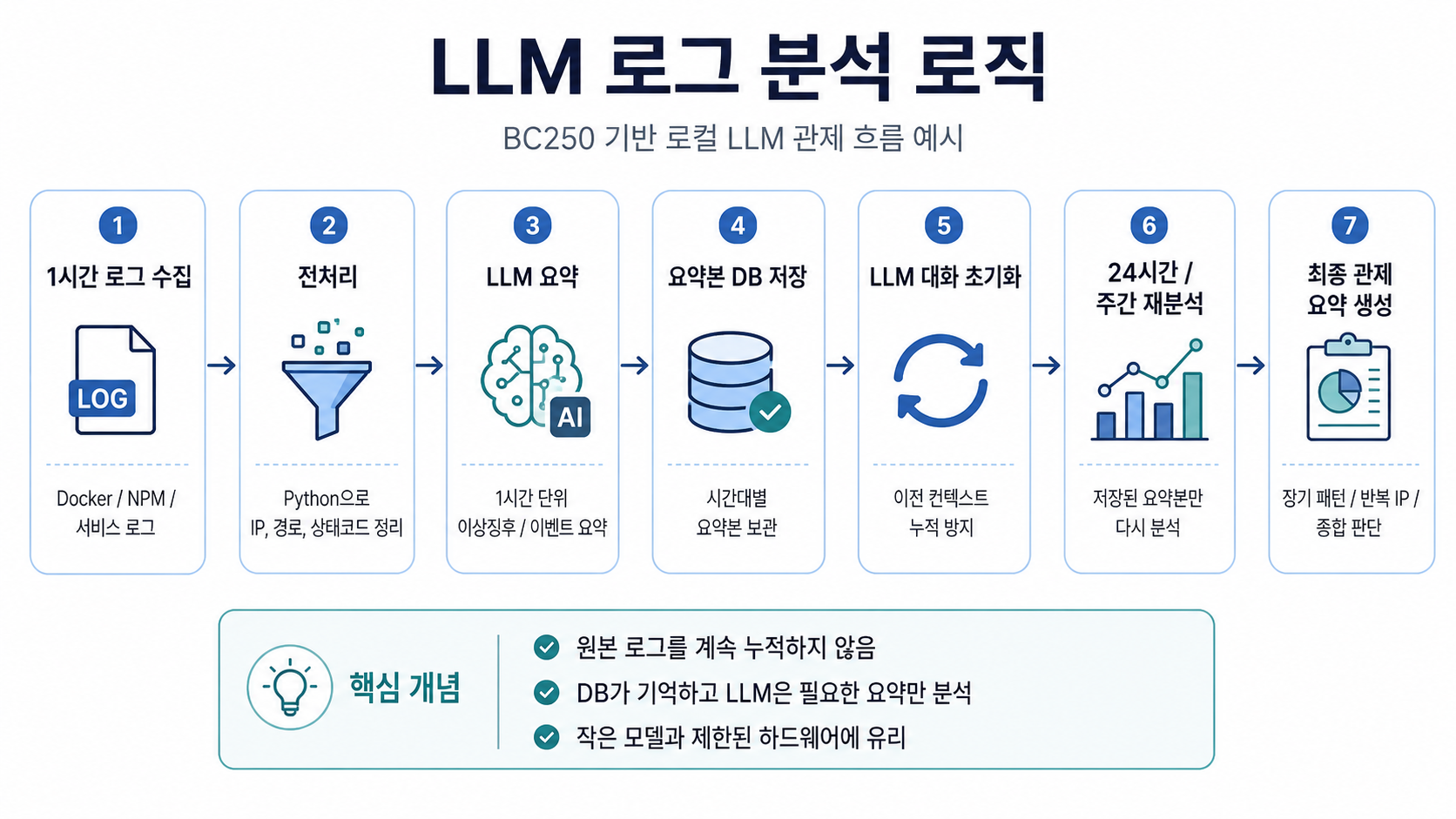
즉 원본 로그를 계속 LLM에게 누적해서 넣는 방식이 아니라,
1시간 단위로 생성한 요약본을 DB나 파일에 저장해두고,
이전 대화는 초기화한 뒤 다음 컨테이너 분석을 진행하고,
24시간/주/년 단위 같은 큰 분석에서는 DB에서 요약된 정보를
필요한 시점에 다시 불러와 재분석하는 방식으로 구성해보려 한다.
개념적으로 보면 인간의 단기 기억과
장기 기억을 나누는 방식과도 비슷하다.
LLM은 현재 분석에 필요한 로그나
요약본만 참고하는 단기 기억 역할을 하고,
DB는 시간대별 요약본과 과거 이력을
저장하는 장기 기억 역할을 맡는다.
이렇게 하면 BC250처럼
메모리와 연산 성능이 제한적인 장비에서도
원본 로그 전체를 매번 처리하지 않고,
필요한 정보만 단계적으로 분석할 수 있다.
앞으로 다뤄야 할 내용이 많기 때문에,
한 포스트에 모든 내용을 담기보다는 진행 과정을 나눠서 정리해볼 예정이다.